

همه پردازنده را مغز کامپیوتر میدانند اما درون این مغز چه خبر است و میلیاردها ترانزیستور درون آن چگونه برنامهها را اجرا میکنند؟
ساده ترین توضیحی که برای نحوه کارکرد پردازنده میتوان ارائه کرد این است که با دنبال کردن مجموعهای از دستورات، عملیاتهای خاصی را روی ورودی ترتیب میدهد. زمانی که میخواهید یک برنامه، بازی یا حتی خود سیستم عامل را اجرا کنید، این موارد در قالب دستورالعملهایی از رم وارد پردازنده شده و در سادهترین حالت به صورت تک تک تا پایان برنامه اجرا میشوند.
برنامههایی که در زبانهای سطح بالا مثل ++C و پایتون نوشته شدهاند، در حالت عادی برای پردازنده قابل درک نیستند، بنابراین ابتدا به عنوان بخشی از «معماری مجموعه دستورات» یا « ISA» به دستورالعملهای سطح پایینی در زبان اسمبلی کامپایل میشوند. ISA نه یک بخش فیزیکی مثل حافظه کش بلکه دستوراتی است که نحوه پردازش، ارتباط با رم و اجرای برنامهها را مشخص میسازد.

متداول ترین نوع ISA شامل معماری x86, MIPS, ARM, RISC-V و PowerPC میشود. همانطور که سینتکس دو برنامه یکسان در زبانهای برنامه نویسی مختلف با هم فرق دارد، هر ISA هم دارای سینتکس خاصی است.
ISAها را میتوان به دو گروه عمده با طول ثابت و متغیر تقسیم کرد. ISA برای RISC یا همان «مجموعه دستورات ساده شده» از دستورات با طول ثابت استفاده میکند و در آن تعدادی معین از بیتها در هر دستورالعمل، نوع دستورات را مشخص میکنند اما معماری x86 از دستورات با طول متغیر استفاده میکند و به همین خاطر دکودر دستورات در پردازندههای مبتنی بر این معماری پیچیدهترین بخش در کل طراحی است.
اجرای یک دستور دارای چند بخش اساسی است که درون پردازنده طی مراحل مختلفی انجام میشوند. اولین مرحله دریافت دستورات از رم و دومین مرحله رمزگشایی آن برای تعیین نوع دستور است چرا که دستورات به انواع بسیار مختلفی مثل حسابی، انشعابی، حافظهای و غیره تقسیم میشوند. پس از تعیین نوع نوبت به جمع آوری عملوندها از رم یا رجیستر CPU میرسد.
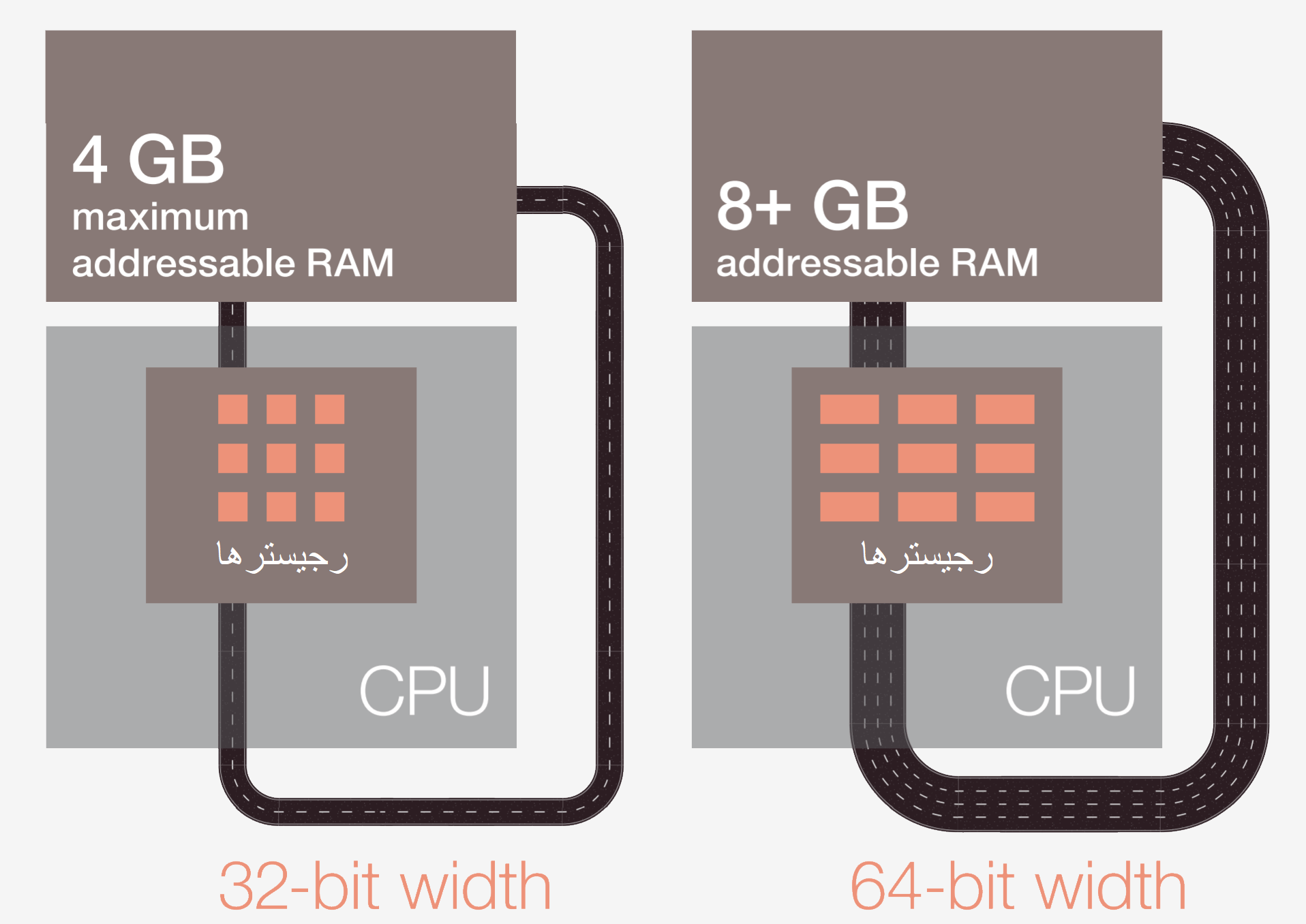
اگر مثلا دستور جمع A و B باشد، تا زمانی که مقادیر آنها مشخص نشود نمیتوان اینکار را انجام داد. اغلب پردازندههای مدرن ۶۴ بیتی هستند بدین معنا که اندازه هر مقدار داده ۶۴ بیت است. پس از انجام محاسبه میتوان آنرا در رم یا رجیستر داخلی پردازنده ذخیره کرد. در مرحله بعد CPU حالت چند عنصر مختلف را به روز کرده و سراغ دستور بعدی میرود.
روال کار البته به این راحتی نیست و آنرا به سادهترین شکل توضیح دادیم وگرنه در پردازندههای این چند ساله هر محله به ۲۰ بخش هم تقسیم میشود تا بازده کار بالاتر برود. این مدل معمولا «پایپلاین» به معنی خط لوله نامیده میشود چون پر شدن آن مثل لولهای حاوی مایع کمی زمان میبرد اما پس از تکمیل روند جریانی ثابت از خروجی خواهیم داشت.
کل سیکل یا چرخهای که دستور طی میکند به دقت و هماهنگ طراحی شده اما زمان اجرای آنها یکسان نیست. برای مثال عمل جمع خیلی سریع انجام میگیرد اما تقسیم یا بارگذاری از مموری شاید نیاز به صدها چرخه داشته باشد. پردازندهها در این موارد به جای متوقف کردن فرایند پردازش تا زمان پایان یک دستور کند، دستورات سریع را شناسایی کرده و خارج از نوبت اجرا میکنند. در این حین دستوراتی که آماده نشده بافر میشوند تا سرعت پردازش بیشتر شود.
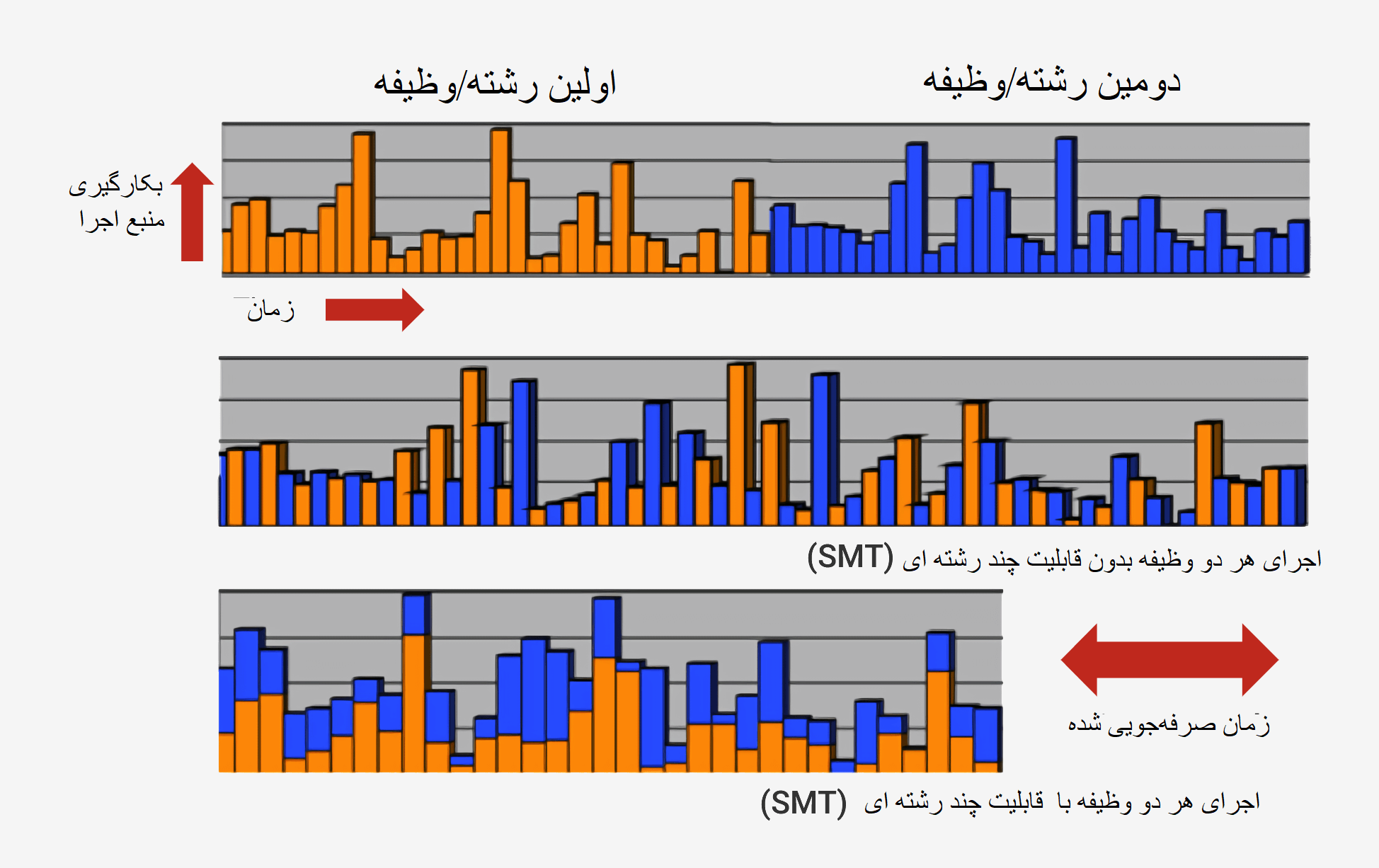
یکی از ترفندها برای افزایش سرعت معماری « سوپر اسکالر» است که به پردازنده اجازه میدهد در هر سطح از پایپلاین همزمان دستورات زیادی را اجرا کند. پردازنده بدین منظور باید از هر سطح پایپلاین چندین کپی درون خود داشته باشد. در این حالت اگر CPU تشخیص دهد دو دستور آماده اجرا هستند و بین آنها هیچ وابستگی وجود ندارد، به جای آنکه منتظر تمام شدن جداگانه آنها بماند، هر دو را در یک زمان اجرا میکند.
یکی از روشهای مرسوم در پیاده سازی سوپر اسکالر، چند رشتهای همزمان یا SMT است که به عنوان هایپر ثردینگ هم شناخته میشود. پردازندههای اینتل و AMD در حال حاضر از SMT دو مسیره پشتیبانی میکنند اما IBM تراشههایی را توسعه داده که قادر به پشتیبانی از IBM هشت مسیره هم هستند.
پردازنده برای اجرای دقیق این روندها به اجزایی بیشتر از هسته نیاز دارد. در هر CPU با میلیاردها ترانزیستور از نوع pMOS و nMOS صدها ماژول مجزا وجود دارد که هر کدام برای هدف خاصی طراحی شدهاند. طبیعتا بررسی همه این عناصر از حوصله این مطلب خارج است و تنها به بخشهای مهمتر میپردازیم. دو عنصر اصلی و مهم هر پردازنده کش و پیشبینی کننده انشعاب یا پرش است که در ادامه بیشتر درباره آنها توضیح میدهیم. از دیگر اجزای مهم دیگر باید به بافر رکوردر، واحد محاسبه و منطق (ALU)، جداول RAT و ایستگاههای رزرو اشاره کرد.
کشها هم مثل رم و SSD وظیفه ذخیره داده را بر عهده دارند اما سرعت آنها به مراتب بالاتر بوده و تاخیر بسیار کمتری دارند. با تمام سرعتی که RAM دارد، جوابگوی نیاز پردازنده نیست و دسترسی به دادههای آن به صدها چرخه نیاز دارد که در این صورت پردازنده مدت زیادی معطل میشود. این مورد در مورد SSD هم صادق است و به همین خاطر بخشی از دادههای اصلی مورد نیاز پردازنده، در حافظه سریع کش ذخیره میشود.
پردازندهها معمولا دارای ۳ سطح کش هستند که از آن با عنوان سلسله مراتب حافظه یاد میشود. کش سطح اول یا L1 کوچکترین و سریعترین است، L2 در میانه قرار گرفته و در نهایت L3 بزرگترین و کندترین سطح بین کشها است. در سلسله مراتب حافظه بالاتر از کشها رجیسترهای کوچکی قرار گرفتهاند که تنها برای ذخیره مقادیر واحد داده طی محاسبه بکار میروند. در سیستم شما این رجیسترها سریع ترین واحد ذخیره سازی هستند. زمانی که کامپایلر برنامههای سطح بالا را به زبان اسمبلی تبدیل میکند، بهترین روش برای استفاده از رجیسترها را نیز معین خواهد کرد. در ساخت حافظه کش و رجیسترها معمولا از SRAM استفاده میشود که خود آن با استفاده از چند ترانزیستور طراحی میشود.
در پردازندههای رایج هر هسته دارای دو کش L1 است که یکی برای داده و دیگری برای دستورات به کار میرود. کشهای L1 حدود ۱۰۰ کیلو بایت ظرفیت دارند اما در نسلهای مختلف این مقدار متغیر است. هر هسته همچنین دارای یک کش L2 است اما در برخی معماریها دو هسته به صورت مشترک از یک کش L2 چند صد کیلوبایتی استفاده میکنند. در نهایت تمام هستهها به صورت مشترک از یک کش سطح ۳ استفاده میکنند که چند ده مگابایت ظرفیت دارد.
حین اجرای یک کد توسط پردازنده، مقادیر داده و دستوراتی که به صورت مکرر از آن استفاده میکند کش میشوند. اینکار CPU را از مراجعه مداوم به رم بی نیاز کرده و سرعت پردازش را به شکل چشمگیری ارتقا میدهد.
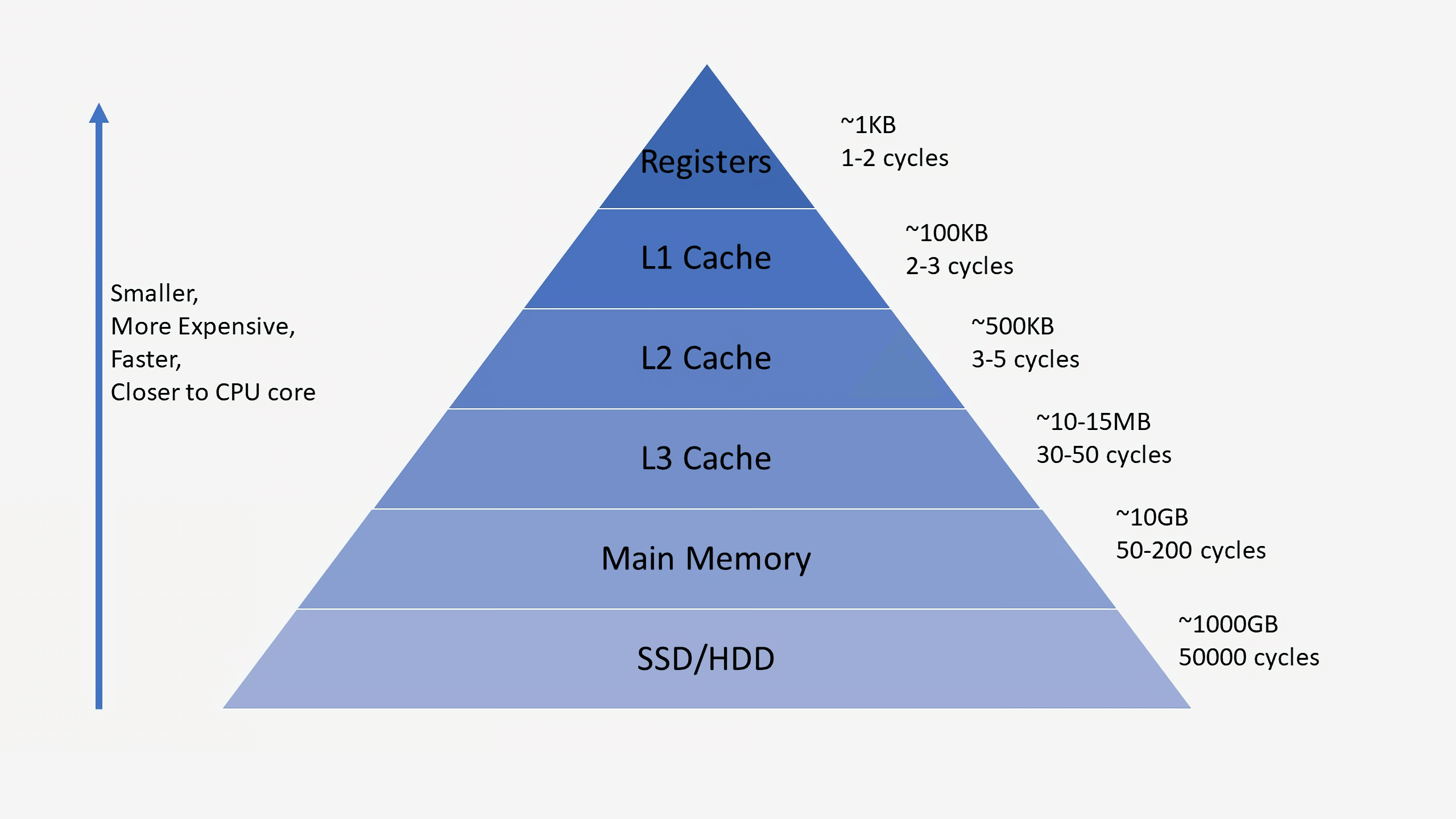
حین واکشی اطلاعات توسط CPU، ابتدا وجود داده در کش L1 بررسی میشود. در صورتی که جواب مثبت باشد، داده تنها طی چند سیکل در دسترس قرار میگیرد اما در غیر این صورت، به ترتیب کشهای L2 و L3 بررسی میشوند. ساختار کشها به گونهای پیاده شده که برای هسته کاملا شفاف باشد. زمانی که هسته خواستار دریافت داده از آدرس خاصی در حافظه میشود، هر سطح از سلسله مراتب که دارای آن باشد پاسخ خواهد داد. با هر سطح پایین رفتن در سلسله مراتب سرعت کاهش یافته و تاخیر بیشتر میشود، تنها در صورتی که داده مورد نظر در کش نباشد، پردازنده به سراغ رم خواهد رفت.
همانطور که گفتیم جدای از کش یک بخش کلیدی دیگر به نام پیشبینی کننده انشعاب یا پرش در پردازنده وجود دارد. دستورات انشعاب شبیه به گزاره «اگر» هستند، بدین صورت که اگر یک شرط خاص برقرار باشد مجموعهای از دستورات و اگر آن شرط برقرار نباشد، مجموعه دیگری از دستورات توسط پردازنده اجرا میشوند. برای مثال دو عدد را با هم مقایسه میکنید و اگر برابر بودند یک دستور و اگر برابر نبودند یک دستور دیگر اجرا میشوند. انشعابها در دنیای کامپیوتر بسیار رایجند و تقریبا ۲۰ درصد از کل دستورات یک برنامه را شامل میشوند.
شاید در نگاه اول انشعاب بسیار ابتدایی به نظر برسد اما برای پردازندهها بسیار چالش برانگیز هستند چرا که گاهی CPU باید به صورت همزمان ۱۰ تا ۲۰ دستور را به صورت همزمان اجرا کند و در این سناریو تشخیص درست انشعاب و انتخاب شرط بر اساس آن بسیار مهم است. تعیین اینکه یک دستور از نوع انشعاب است حدود ۵ سیکل و تعیین درست بودن شرط هم به ۱۰ سیکل دیگر نیاز دارد. در این زمان پردازنده ممکن است اجرای دهها دستور اضافی را شروع کرده باشد، بدون اینکه از سازگاری آن با انشعاب مطمئن باشد.
پردازندههای مدرن برای غلبه بر این مشکل از تکنیک حدس و گمان استفاده میکنند.در این تکنیک پردازنده دستورات انشعاب را رهگیری کرده و دریافت یک انشعاب خاص را حدس میزند. اگر حدس درست از آب درآید، پردازنده از قبل دستورات متعاقب آنرا شروع کرده و در نتیجه کار سریعتر پیش میرود. اما اگر حدس غلط باشد، پردازنده اجرا را متوقف کرده، تمام دستورات اشتباه را حذف کرده و کار را از نقطه درست دنبال میکند.
پیش بینی کننده انشعاب یکی از فرمهای اولیه یادگیری ماشین است چرا که رفتار انشعاب را در طول اجرا یاد میگیرد و در صورتی که دفعات زیادی پیش بینی نادرست باشد، شروع به یادگرفتن رفتار درست میکند. دهها تحقیق در مورد این تکنیک باعث شده پردازندههای امروزی با دقت بالای ۹۰ درصد رفتار انشعاب را پیش بینی کنند.
حدس و گمان با تمام مزایایی که دارد، سیستم را در معرض ریسکهای امنیتی قرار میدهد. حمله معروف اسپکتر که مدتها نقل محافل کامپیوتری بود از باگهایی در پیش بینی کننده انشعاب و حدس و گمان سوءاستفاده میکند. برای رفع این آسیب پذیری چارهای جز باز طراحی سیستم حدس و گمان نبود که علی رغم کاهش نسبی کارایی، مانع نشت اطلاعات میشود.
معماری مورد استفاده از پردازندهها طی دههای گذشته تغییرات بسیاری به خود دیده و نوآوریها باعث شده کارایی آن و سرعت محاسبات به شکلی باورنکردنی ارتقا پیدا کند. فضای شدیدا رقابتی باعث شده تولیدکنندگان پردازنده در مورد سازوکار محصولاتشان مخفی کاری کنند و به همین خاطر تشخیص کل سازوکار محاسبات درون پردازنده ناممکن است با این حال همه شرکتها از جمله اینتل و AMD تقریبا از روش یکسانی پیروی میکنند که در این مطلب شرح داده شد.












