

بدون تردید CPU پیچیدهترین بخش کامپیوتر محسوب میشود. آیا میدانید معماری و ساختار فیزیکی CPU چگونه است؟ این قطعه از چه بخشهایی تشکیل شده است؟ بخشهای مختلف آن چگونه با یکدیگر ارتباط برقرار میکنند؟ اطلاعات را چگونه پردازش میکند و دادههای موردنیاز برای پردازش اطلاعات چگونه در دسترس آن قرار میگیرند. در این مطلب با بیان آناتومی ساده و مختصر CPU به تمام این سؤالات پاسخ خواهیم داد.
CPU معمولا مغز کامپیوتر نامیده میشود و درست مانند مغز انسان از بخشهای مختلفی تشکیل شده است که با کمک یکدیگر اطلاعات را پردازش میکنند. برخی از بخشها برای جمعآوری اطلاعات و برخی برای ذخیرهسازی، برخی برای پردازش اطلاعات و برخی دیگر برای تهیه اطلاعات خروجی به کار گرفته میشوند.
در این مطلب قصد داریم CPU را کالبدشکافی و آناتومی آن را بهصورت ساده و خلاصه بیان کنیم تا ببینیم از چه بخشهایی تشکیل شده و این بخشها چگونه با یکدیگر کار میکنند. در حقیقت در این مقاله و بخشهای اساسی CPU را بررسی میکنیم و یک سری اطلاعات مفید در مورد آنها ارائه میدهیم.

یکی از تفاوتهای اصلی سیپییو با سایر قطعات کامپیوتر این است که بخشهای تشکیلدهنده آن مانند بخشهای سایر قطعات کامپیوتر بهوضوح قابلمشاهده نیست؛ بهعنوانمثال شما وقتی پاور کامپیوتر را میبینید، بهراحتی میتوانید خازنها، ترانسفورماتورها و سایر قطعات تشکیلدهنده آن را بهراحتی مشاهده کنید؛ اما در مورد CPU اینچنین نیست؛ زیرا از یک سو تمام قطعات تشکیلدهنده سیپییوهای مدرن بسیار کوچک هستند و از سوی دیگر اینتل و AMD، تنها شرکتهای تولیدکننده سیپییوی کامپیوتر در جهان، اطلاعات مرتبط با طراحیهای خود را منتشر نمیکنند و اکثر طراحیهای سیپییوهای این دو شرکت، مختص خود آنها است.
قبل از اینکه بررسی آناتومی CPU را آغاز کنیم باید خاطرنشان کنیم که هر سیستم دیجیتالی نیازمند یک واحد پردازش مرکزی (Central Processing Unit) یا همان CPU است. اساساً هر برنامهنویسی برای انجام فعالیتهای مختلف توسط این نرمافزار طراحیشده توسط خود، باید کدهایی را بنویسد و وظیفه اجرای کدها برای انجام وظایف مربوطه در نرمافزار، بر عهده CPU است. درضمن CPU به سایر بخشهای سیستم مثل حافظه و سوکت مرتبط به ورودی و خروجی (سوکتی که CPU را به سایر بخشهای کامپیوتر از طریق کابل متصل میکند) متصل میشود تا اطلاعات لازم را در اختیار آنها قرار دهد.
ساختار CPU
زمانی که میخواهیم ساختار CPU را بررسی کنیم، نخستین بخشی که باید به آن بپردازیم، معماری مجموعه دستورالعملی یا Instruction Set Architecture (ISA) یا به بیان سادهتر معماری یا معماری کامپیوتر است.
این مفهوم در حقیقت مدلی تصویری از نحوه کار CPU و همچنین چگونگی نحوه تعامل سیستمهای داخلی CPU با یکدیگر را توضیح میدهد. معماری مجموعه دستورالعملی درست مانند نژادهای مختلف یک حیوان هستند که با اینکه با یکدیگر تفاوت دارند، اما تمام آنها متعلق به یک گونه هستند. در حقیقت معماریهای مجموعه دستورالعملی، معماریهای مختلفی محسوب میشوند که یک CPU بر اساس آنها میتواند ساخته شود.
معماری ۳۲ بیتی (که در کامپیوترهای دسکتاپ و لپتاپها استفاده میشود) و ARM، معماری مورداستفاده برای ساخت پردازندههای مورداستفاده دردستگاههای موبایل و دستگاههای تعبیهشده در دستگاههای دیگر)، متداولترین نوع معماریها برای ساخت CPU هستند.
معماریهای دیگری نیز برای ساخت CPU وجود دارد که از میان آنها میتوان به MIPS و RISC-V و PowerPC اشاره کرد؛ اما این معماریها در موارد معدودی و تنها برای ساخت برخی از پردازندهها استفاده میشوند.
در حقیقت معماری مجموعه دستورالعمل وظایفی مثل تعیین دستورالعملهایی که CPU میتواند آنها را پردازش کند، تعیین چگونگی نحوه برقراری ارتباط CPU با حافظه و تراشهها و همچنین چگونگی تقسیم وظایف بین بخشهای مختلف درگیر با مراحل مختلف پردازش اطلاعات و سایر موارد را بر عهده دارد.

برای بررسی بخشهای اصلی CPU، مراحلی را که از هنگام اعمال یک دستورالعمل تا اجرای آن طی میشوند، بررسی میکنیم. طبیعتاً ممکن است برای اجرای دستورالعملهای مختلف مراحل و مسیرهای متفاوتی استفاده شوند و بخشهای مختلفی درگیر شوند؛ اما در این مقاله بزرگترین و مهمترین بخشها را بررسی میکنیم در ابتدا ابتداییترین طراحی یک CPU تکهستهای را بررسی میکنیم و سپس بهتدریج سراغ طراحیهای پیچیدهترسیپییوهای مدرن میرویم.
اجزای تشکیلدهنده CPU را میتوان به دو دسته تقسیم کرد: ابزارهای مرتبط با واحد کنترل (Control Unit) و اجزای مرتبط با آن مسیر داده یا دیتاپد (datapath). اجازه دهید ساختار CPU را با ساختار یک واگن قطار مقایسه کنیم. واگن برای حرکت کردن از موتور استفاده میکند و لوکوموتیوران هم هدایت قطار را بر عهده دارد و بخشهای مختلف موتور را کنترل میکند.
مسیر داده همانطور که از نامش پیدا است، مانند موتور واگن عمل میکند و در حقیقت مسیری برای انتقال دادهها در جریان پردازش دادهها محسوب میشود. در حقیقت اجزای درگیر در بخش مسیر داده ورودیها را دریافت و آنها را پردازش میکنند و پس از اتمام پردازش آنها، این اطلاعات را به بخشی که باید ارسال کنند، میفرستند.
اجزای درگیر در بخش واحد کنترل نیز مانند لوکوموتیوران، اطلاعات لازم در مورد نحوه پردازش اطلاعات توسط مسیر داده را در اختیار این بخش قرار میدهند، مسیر داده بسته به نوع دستورالعمل سیگنالهایی را برای اجزای مختلف ارسال و بخشهای مختلف درگیر با این بخش را نیز روشن خاموش میکند. در ضمن این بخش نظارت بر وضعیت CPU را نیز بر عهده دارد.
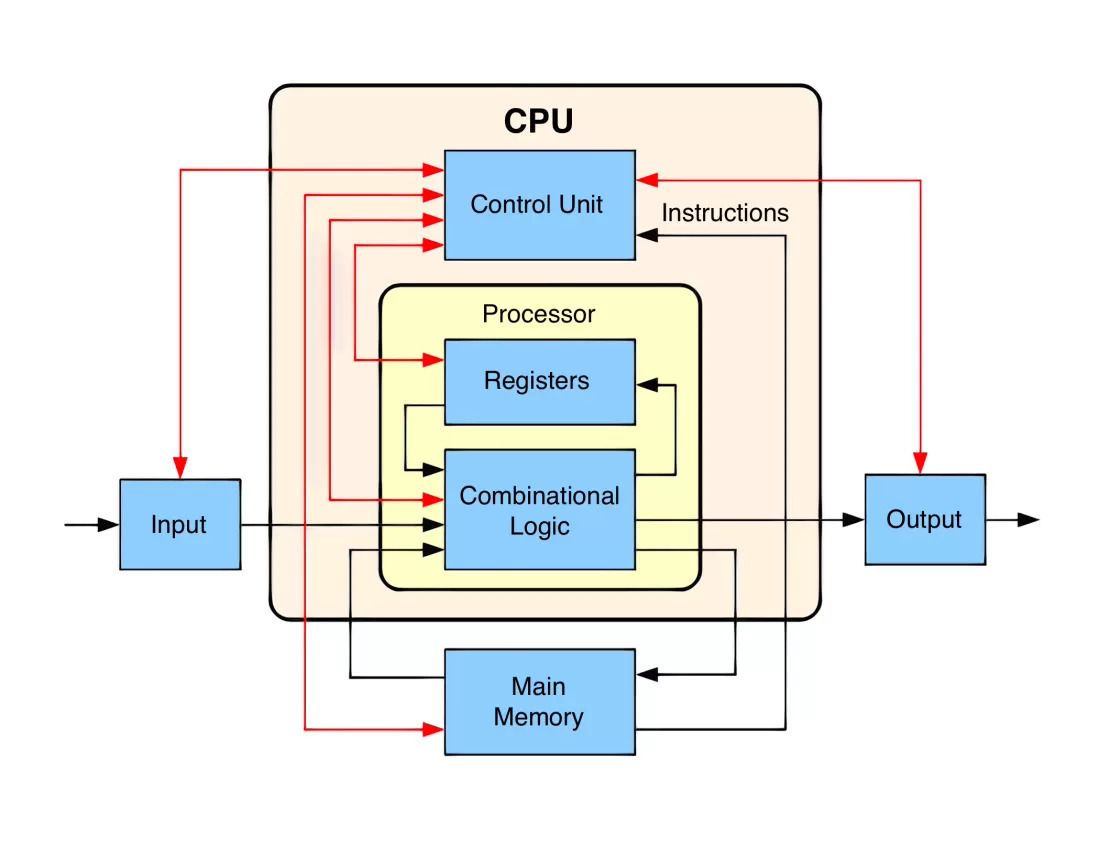
این نقشه نقشه بلوکی یک CPU کاملاً ساده و ابتدایی است. خطوط سیاه نشاندهنده جریان داده و خطوط قرمز نشاندهنده جریان کنترل هستند. در ادامه بیشتر با بخشهای مختلف این نقشه آشنا میشویم.
سیکل دستورالعمل
اولین کاری که یک CPU باید انجام دهد، تشخیص دستورالعملهای است که باید در مرحله بعدی انجام دهد و در گام بعدی باید این دستورالعملها را از حافظه سیستم به حافظههای خود منتقل کند. دستورالعملها توسط یک کامپایلر (کامپایلر مجموعهای از برنامههای کامپیوتری محسوب میشود که متنی از یک زبان برنامهنویسی سطح بالا را به زبان برنامهنویسی سطح پایین منتقل میکند) ایجاد میشوند و مختص معماری مجموعه دستورالعمل سیپییو هستند.
معماریهای مجموعه دستورالعملی متداولترین نوع دستورالعملها مثل بارگذاری، ذخیره کردن، اضافه کردن و تفریق و سایر موارد مشابه را به اشتراک میگذارند؛ اما بسیاری از دستورالعملهای خاص تنها مختص یک معماری مجموعه دستورالعملی خاص هستند.
وظیفه هدایت سیگنالهای خاص به بخشهای خاص برای انجام هر یک از دستورالعملها بر عهده بخش واحد کنترل است؛ بهعنوانمثال زمانی که یک فایل نصبی با پسوند exe را در ویندوز اجرا میکنید. کد برنامه به حافظه سیستم منتقل میشود و آدرسی که نخستین دستورالعمل در آن آغاز میشود، در اختیار CPU قرار میگیرد. رجیستر داخلی که دربردارنده موقعیت دستورالعمل بعدی لازمالاجرا توسط CPU در حافظه سیستم است، همبشه در CPU حفظ می شود. این رجیستر داخلی شمارنده برنامه (Program Counter) یا بهاختصار PC نام دارد.
زمانی که چرخه یا سیکل اجرای دستورالعمل شروع میشود، نخستین مرحله از این چرخه دریافت دستورالعمل است. در این مرحله که مرحله فِچ (Fetch stage) نام دارد، دستورالعمل از حافظه سیستم به بخش رجیستر دستورالعمل CPU منتقل میشود. در ادامه کمی در مورد این فرایند توضیح میدهیم
چرخه دستورالعمل رمزگشایی (Decode)
زمانی که CPU دستورالعمل را در اختیار دارد، باید نوع دستورالعمل را بهدقت تشخیص دهد. این مرحله، مرحله رمزگشایی (Decode stage) نام دارد. هر یک از دستورالعملها دربردارنده بیتهای خاصی از دادهها تحت عنوان کد دستور یا آپ کد (Operation Code یا بهاختصار OPcode هستند که اطلاعات لازم برای تفسیر دستورالعمل را در اختیار CPU قرار میدهند.
اطلاعاتی که این بیتهای داده در اختیار CPU قرار میدهند، مانند اطلاعاتی هستند که نحوه استفاده از افزونههای فایل متفاوت برای تعیین روش تفسیر یک فایل توسط کامپیوتر را مشخص میکنند. اجازه دهید برای فهم بهتر این موضوع مثالی را بیان کنیم. همانطور که میدانید پسوندهای jpg و png هردو پسوند فایلهایعکس هستند؛ اما دو پسوند دادهها را به شکل متفاوتی سازماندهی میکنند؛ بنابراین کامپیوتر برای اینکه بتواند دادهها را درست تفسیر کنند، باید نوع آنها را تشخیص دهد.
بخش مربوط به رمزگشایی دستورالعمل مربوط بسته به اینکه معماری مجموعه دستورالعمل چقدر پیچیده است، ممکن است کمی پیچیدهتر شود. برخی از معماریها شبیه RISC-V ممکن است تنها در حد چند دستورالعمل داشته باشند؛ اما برخی دیگر از معماریها مانند معماری ۳۲ بیتی هزاران دستورالعمل دارند. در یک سیپییوی ۳۲ بیتی اینتل معمول و متداول، پردازشهای مربوط به رمزگشایی دادهها جزئیات بسیار چالشبرانگیز هستند و دادههای مربوط به این پردازشها فضای زیادی را اشغال میکنند. متداولترین نوع دستورالعملهایی که یک CPU میتواند آنها را رمزگشایی کند، دستورالعملهای مرتبط با حافظه (memory instructions)، دستورالعملهای حسابی یا محاسباتی (arithmetic instructions) و دستورالعملهای انشعاب (branch instructions) هستند.
سه نوع اصلی دستورالعملها
دستورالعمل حافظه ممکن است دستورالعملی شبیه خواندن داده از حافظه آدرس ۱۲۳۴ در مقدار A یا نوشتن مقدار B در آدرس حافظه ۵۶۷۸ باشد. دستورالعمل حسابی یا محاسباتی ممکن است چیزی شبیه افزودن مقدار A به مقدار C و ذخیره کردن نتیجه جمع این دو مقدار در مقدار C است.
دستورالعمل انشعاب نیز فرآیندی شبیه به اجرای این کد در صورت مثبت بودن مقدار C و اجرا کردن آن کد در صورت منفی بودن مقدار C است (منظور دو کد متفاوت است) است. یک برنامه معمول و متداول ممکن است این دستورالعملها را برای انجام عملیاتی مثل افزودن مقدار ایجادشده در آدرس حافظه ۱۲۳۴ به مقدار ایجادشده در آدرس حافظه ۵۶۷۸، در کنار یکدیگر به صورت یک زنجیره اجرا کند. پس از انجام. پس از انجام این عملیات، نتیجه درصورتیکه مثبت باشد باید در آدرس حافظه ۴۳۲۱ ذخیره و درصورتیکه منفی باشد، باید در آدرس حافظه ۸۷۶۵ ذخیره شود. قبل از اینکه بیشتر با این سه نوع اصلی دستورالعملهای CPU آشنا شویم، اجازه دهید ابتدا در مورد رجیسترها نیز توضیح دهیم.
در CPU حافظههای بسیار کمظرفیت اما بسیار سریعی تحت عنوان رجیستر ها وجود دارند. ظرفیت هر یک از رجیسترها در یک سیپییوی ۶۴ بیتی ۶۴ بیت است و در چنین پردازندهای رجیسترهای کمی برای هسته سیپییو ایجاد شده است. ریجستر ها برای ذخیرهسازی مقادیری به کار گرفته میشوند که در حال استفاده هستند و میتوان گفت رجیسترها کش L0 سیپییو محسوب میشوند (در ادامه با سطوح مختلف حافظه کش آشنا میشویم).
واحدهای محاسبه و منطق
در بخش قبلی با سه نوع دستورالعمل اصلی بر سیپییو یعنی دستورالعملهای مرتبط با حافظه، دستورالعملهای حسابی یا محاسباتی و دستورالعملهای انشعاب تا حدودی آشنا شدیم. در این بخش قصد داریم در مورد هر یک از آنها بهصورت جداگانه توضیح دهیم.

این بخش را ابتدا با توضیح در مورد دستورالعملهای حسابی شروع میکنیم؛ زیرا فهم آن نسبت به دستورالعمل دیگر سادهتر است. اجازه دهید برای فهم بهتر ساختار این دستورالعمل مثال سادهای را بیان کنیم. برای کار با ماشینحسابهای سادهای که معمولاً دانش آموزان دوره متوسطه اول یا همان دانش آموزان راهنمایی از آنها استفاده میکنند، تنها کافی است دو عدد را وارد و با زدن دکمههای مربوط به عملیات مختلف، محاسبات را با ماشینحساب انجام دهید و نتیجه را مشاهده کنید.
ماشینحساب پس از انجام این فرایند محاسبه را انجام میدهد و نتیجه را به شما نمایش میدهد. برای انجام چنین عملیاتی در واحدهای محاسبه و منطق CPU، نوع دستورالعمل توسط کد دستور آن مشخص میشود و واحد کنترل کد دستور را به واحد محاسبه و منطق ارسال میکند.
واحدهای محاسبه و منطق علاوه بر انجام عملیات محاسباتی ساده و ابتدایی میتوانند عملیات بیتی (عملیاتی که روی تکتک بیتهای یک عدد دودوبی یا همان مقدار 0 و 1 یا هرگونه الگوی بیتی دیگری انجام میشود) مثل عملیات AND، OR، NOT و XOR را نیز انجام دهند. این واحدهای محاسباتی توانایی ارائه اطلاعات مرتبط با وضعیت محاسبات تازهانجامشده برای واحد کنترل را نیز دارند. این اطلاعات که در قالب دادههای خروجی واحدهای محاسبه و منطق ارائه میشوند، نشان میدهند که آیا نتیجه محاسبه مثبت یا منفی یا صفر بوده یا حتی نتیجه محاسبه عدد سرریزی بوده است (منظور از عدد سرریز عددی فراتر از محدوده مجاز قابلپردازش است)
واحدهای محاسبه و منطق مرتبطترین بخشهای سیپییو با دستورالعملهای حسابی محسوب میشوند؛ اما ممکن است گاهی مواقع برای انجام دستورالعملهای حافظه یا انشعاب نیز استفاده شوند؛ بهعنوانمثال ممکن است سیپییو نیازمند محاسبه آدرس حافظهای باشد که بهعنوان نتیجه عملیات حسابی قبلی در اختیار آن قرار گرفته باشد.
همچنین ممکن است نیازمند محاسبه آفسِت یا offset (منظور از آفست فاصله اطلاعات یا یک دستور از ابتدای سگمنت، ناحیهای از حافظه، است) برای اضافه کردن آن به شمارنده برنامهای باشد که دستورالعمل انشعاب به آن نیاز دارد. ممکن است سیپییو پس از انجام محاسبه به این نتیجه برسد که اگر نتیجه منفی بود، باید ۱۹ محاسبه پس از آن را رد کرد و به سراغ بیستمین محاسبه برود.
دستورالعملهای حافظه و سلسلهمراتب آن
برای فهم بهتر دستورالعملهای حافظه ابتدا باید مفهوم سلسلهمراتب حافظه (Memory Hierarchy) را بهدرستی درک کنیم. این مفهوم نشاندهنده ارتباط بین سطوح مختلف حافظه کش سیپییو، رم و حافظه اصلی سیستم یا همان هارد سیستم است.
زمانی که CPU یک دستورالعمل حافظه مرتبط با دادهای را دریافت میکنند که آن داده هنوز در ریجسترهای داخل CPU قرار نگرفته است، تلاش میکند آن داده را در سطوح پایینتر سلسلهمراتب حافظه یا بهبیاندیگر سطوح پایینتر حافظههای کش خود پیدا کند. مدرنترین سیپییوها دارای سه سطح از حافظه کش یعنی کش L1 و L2 و L3 هستند. سیپییو برای جستجوی داده در حافظههای کش خود ابتدا کش L1 را بررسی میکند که کمظرفیتترین اما سریعترین سطح حافظه کش محسوب میشود.
کش L1 معمولاً به دو قسمت تقسیم میشود که یکی آنها به دادهها و دیگری به دستورالعملها اختصاص پیدا میکند. یادآوری میکنیم که دستورالعملها نیز باید مانند دادهها از حافظه دریافت شوند.
یک حافظه کش L1 متداول معمولاً تنها چند کیلوبایت ظرفیت دارد. چنانچه CPU موفق به یافتن دادههای موردنظر خود در کش L1 نشد، سراغ کش L2 میرود (ممکن است ظرفیت این سطح کش در حدود چند مگابایت باشد)؛ اگر جستجو در کش L2 هم جواب نداد، درنهایت کش L3 را نیز جستجو میکند که ظرفیت آن در حدود چند ده مگابایت است؛ چنانچه CPU با جستجو در کش L3 هم موفق به یافتن دادههای موردنظر خود نشد، جستجو را در حافظه رم ادامه میدهد و در صورت موفق نشدن در نهایت سراغ حافظه اصلی سیستم میرود.
هر یک از این سطوح حافظه نسبت به سطح قبلی خود ظرفیت بیشتری دارند؛ اما در مقابل جستجو در آنها برای یافتن دادههای موردنظر بیشتر طول میکشد؛ زیرا سیپییو باید برای یافتن دادههای موردنظرش، تمام فضای حافظه را جستجو کند. در تصویر زیر میتوانید سلسلهمراتب سطوح مختلف حافظههایی را که CPU آنها را برای یافتن دادههای موردنظر خود جستجو میکند، مشاهده کنید.
CPU پس از جستجوی داده موردنظر خود، آن را به سطوح بالاتر سلسلهمراتب حافظه انتقال میدهد تا در صورتی که در آینده به آن نیاز پیدا کرد، دسترسی سریعتر و راحتتری به آن داشته باشد. برای انتقال داده موردنیاز سیپییو به سطوح بالاتر حافظههای سیستم مثل کش L1 و L2 مراحل زیادی باید طی شود؛ اما در مقابل دسترسی سریع CPU به دادههای موردنیازش در آینده تضمین میشود.
اجازه دهید برای فهم بهتر این موضوع مثالی را بیان کنیم. CPU میتواند دادههای ذخیرهشده در ریجسترهای داخلی خود را تنها در یک یا دو سیکل بخواند؛ اما تعداد سیکلهای خواندن اطلاعات در کش L1 به چند سیکل معدود، در کش L2 به چند ده سیکل یا همین حدود، در کش L3 به ۱۲ سیکل یا همین حدود میرسد؛ اما در صورتی که CPU مجبور شود دادههای ذخیرهشده در حافظه رم و حافظه اصلی سیستم را نیز بخواند، تعداد سیکلهای خواندن اطلاعات در این دو سطح از حافظه به دهها هزار یا حتی میلیونها سیکل هم میرسد که باعث افزایش تأخیر در یافتن اطلاعات موردنظر میشود.

در هر CPU بسته به ساختار آن هر هسته دارای کش L1 مختص به خود است و دادههای ذخیرهشده در کش L2 خود را با هسته دیگری به اشتراک میگذارد و دادههای ذخیرهشده در کش L3 را نیز با چهار هسته یا تعداد بیشتری از آنها به اشتراک میگذارند. در ادامه این مقاله در مورد سیپییوهای چندهستهای بیشتر توضیح خواهیم داد.
دستورالعملهای انشعاب و دستورالعملهای پرش (Jump Instructions)
اکنون نوبت توضیح در مورد دستورالعملهای انشعاب است. کدهای برنامههای مدرن همیشه جابجا میشوند و CPU بهندرت میتواند بیش از ۱۲ دستورالعمل بههمپیوسته را بدون ایجاد یک انشعاب اجرا کند. منشأ دستورالعملهای انشعاب، عناصر برنامهنویسی مثل عبارات شرطی یا if-statements (عباراتی که برنامه را برای تصمیمگیری بر اساس معیارهای خاص هدایت میکنند)، لوپها یا for-loops (تکرار شدن بلوک خاصی از کدها به تعداد دفعات مشخص شده) و دستورهای بازگشتی یا return-statements (خارج شدن برنامه از روند فعلی خود و شروع شدن مجدد برنامه از بخشی که فرایند فراخوانده شده است) است.
تمام این دستورالعملها برای متوقف کردن اجرای برنامه و سوئیچ شدن به بخش دیگری از کد در حال اجرا استفاده میشوند. دستورالعملهای پرشی هم آن دسته از دستورالعملهای انشعابی هستند که همیشه مورداستفاده قرار میگیرند. انجام انشعاب شرطی (پرش به قسمت دیگری از برنامه در حال اجرا در صورت محقق شدن یک شرط) همیشه برای CPU دشوار است؛ زیرا باید برای انجام چنین فرآیندی چند دستورالعمل را بهصورت همزمان اجرا کند و ممکن است تنها زمانی بتواند نتیجه دستورالعمل انشعاب را مشخص کند که چند دستورالعمل متوالی را شروع کرده باشد.
برای اینکه کاملاً بفهمید چرا انجام انشعاب شرطی برای CPU دشوار است، باید در مورد مفهوم دیگری نیز صحبت کنیم که آن هم مفهوم لولهکشی یا ایجاد مجرای ارتباطی (pipelining) است. ممکن است تکمیل هر مرحله در چرخه دستورالعمل، بهاندازه چند سیکل طول بکشد. این موضوع به معنای این است که با وجود اینکه یک دستورالعمل از حافظه دریافت شده است، واحدهای محاسبه و منطق هنوز هیچ فعالیتی نمیکنند؛ بنابراین برای به حداکثر رساندن راندمان CPU، هر یک از مراحل چرخه دستورالعمل باید طی یک فرایند پردازشی که لولهکشی نام دارد، به مراحل کوچکتر تقسیم شود.
اجازه دهید برای سادهتر کردن فهم این موضوع، مثال کاملاً سادهای را بیان کنیم. تصور کنید دو دسته لباس را باید بشویید و شستن و خشک شدن هر دسته از لباسها یک ساعت طول میکشد؛ یعنی شستن و خشک کردن دو دسته لباس درمجموع چهار ساعت طول میکشد.
شما برای شستن و خشک کردن لباسها دو راه دارید: یا میتوانید ابتدا لباسهای دسته اول را در ماشین لباسشویی بشویید و پس از تمام شدن شستشوی آنها، لباسها را در خشککن بیندازید و پس از خشک شدن این لباسها، سراغ شستن دسته دوم از لباسها بروید. شستن دو دسته لباس با این روش همان ۴ ساعت طول میکشد؛ اما اگر شستن دسته دوم لباسها را همزمان با خشک شدن دسته اول آنها شروع کنید، دو دسته لباس را میتوانید ظرف مدت سه ساعت هم بشویید و هم خشک کنید.
بنابراین با استفاده از روش دوم هم میتوانید یک ساعت در زمانتان صرفهجویی کنید و هم تعداد دفعات شستن و خشک کردن لباسها را کمتر کنید. اگرچه با استفاده از روش دوم شستن و خشک کردن یک دسته از لباسها هنوز هم دو ساعت طول میکشد؛ اما مدتزمان شستن دو دسته لباس را یک ساعت کاهش میدهد.
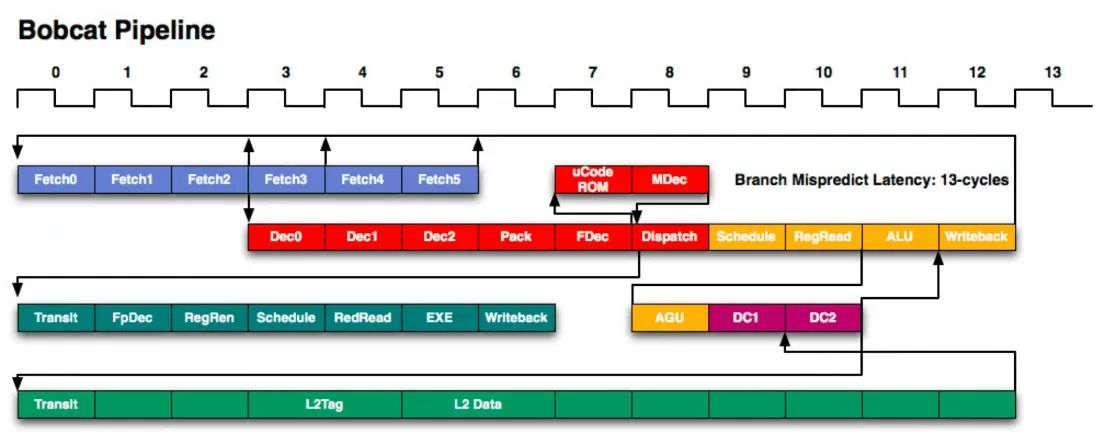
سیپییوها از همین روش برای افزایش توان عملیاتی دستورالعملها استفاده میکنند. یک سیپییوی مدرن با معماری ۳۲ بیتی یا معماری ARM دارای ۲۰ مرحله لولهکشی است. این موضوع به معنای این است که هر هسته در هر لحظه میتواند بیش از ۲۰ دستورالعمل مختلف را پردازش کند.
هر یک از انواع طراحیهای بهکارگرفتهشده برای سیپییوها منحصربهفرد هستند؛ اما یکی از نمونه روشهای تقسیم مراحل به این شرح است: ۴ سیکل برای دریافت و بازیابی دستورالعملها از حافظه، ۶ سیکل برای رمزگشایی، سه سیکل برای اجرا و ۷ سیکل هم برای بهروزرسانی نتایجی که به حافظه سیپییو برگردانده میشوند.
اجازه دهید دوباره به مبحث دستورالعملهای انشعاب باز گردیم. اگر CPU تا سیکل ۱۰ تشخیص ندهد که دستورالعملی که در حال اجرای آن است، یک دستورالعمل انشعاب است، ۹ دستورالعمل قبلی فاقد اعتبار خواهند شد؛ البته برای پیشگیری از مشکل هم یک راهحل کاربردی وجود دارد. سیپییوها دارای ساختارهای بسیار پیچیدهای تحت عنوان پیشبینی کننده انشعاب (branch predictors) هستند. این ساختارها از مفاهیم نشئتگرفته از یادگیری ماشینی استفاده میکنند تا بتوانند حدس بزنند CPU در فرایند پردازش دستورالعملها با دستورالعمل انشعاب مواجه خواهد شد یا نه.
پیشبینیکنندههای انشعاب مفهوم بسیار پیچیدهای هستند و توضیح بیشتر در مورد آنها در این مقاله نمیگنجد؛ اما اگر بخواهیم تعریفی کاملاً ساده و ابتدایی از آنها ارائه دهیم، باید بگوییم این پیشبینیکنندهها وضعیت دستورالعملهای انشعاب قبلی را بررسی و کنترل میکنند تا ببینند سیپییو در هنگام پردازش دستورالعملها با دستورالعملهای انشعاب مواجه خواهد شد یا خیر. دقت پیشبینیکنندههای انشعاب مدرن، ۹۵ درصد یا حتی بالاتر است.
زمانی که یک نتیجه پیشبینی انشعاب کاملاً مشخص شد (مرحله مربوط به لولهکشی را کامل کند) شمارنده برنامه آپدیت خواهد شد و CPU سراغ اجرای دستورالعمل بعدی میرود؛ اما در صورتی که دستورالعمل بهدرستی پیشبینی نشود، CPU اجرای تمام دستورالعملهایی را که آن ها پس از آن دستورالعمل انشعابی که بهاشتباه پیشبینی داده شده است، برای اجرا دریافت کرده است، رها میکند واجرای دستورالعملها را از جایی که دستورالعمل انشعاب بهدرستی تشخیص داده شده است، شروع میکند. چنانچه این جمله شما را گیج کرده است باید بدانید که سیپییو دستورالعملها را از یک صف دریافت میکند و آنها را یکی پس از دیگری اجرا می کند (در ادامه بیشتر در مورد این صف توضیح خواهیم داد)
اکنون که با سه نوع نوع اصلی دستورالعملهای سیپییو کاملاً آشنا شدیم، اجازه دهید کمی هم در مورد برخی از ویژگیهای مدرنتر CPU صحبت کنیم. تقریباً تمام سیپییوهای مدرن دستورالعملها را به همان ترتیبی که دریافت میکنند، اجرا نمیکنند. الگویی که اجرای خارج از ترتیب (out-of-order execution) نام دارد، برای به حداقل رساندن زمان غیرفعال بودن سیپییو (بیکار بودن آن) و انتظار برای اتمام پردازش دستورالعملهای در حال اجرا استفاده میشود.
درصورتیکه CPU تشخیص دهند دستورالعمل بعدی نیازمند دادهای است که در آن لحظه آماده نیست میتواند ترتیب دستورالعملهای در صف انتظار را تغییر دهد و دستورالعملی را قرار است کمی بعد اجرا شود و در صف قرار دارد، انتخاب کند.
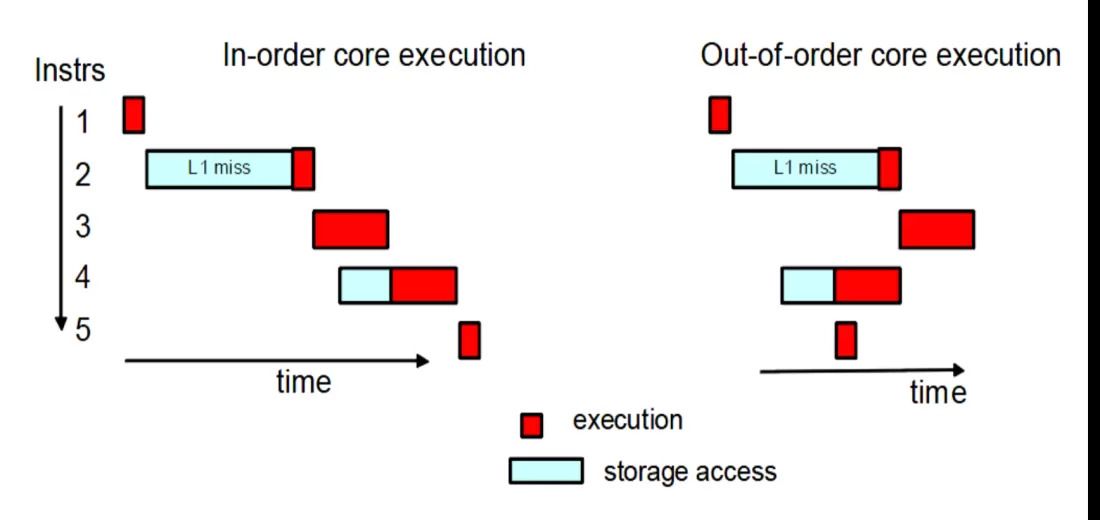
تغییر ترتیب دستورالعملهای موجود در صفحه انتظار برای اجرا شدن، ابزاری قوی برای بهبود عملکرد CPU محسوب میشود؛ اما سیپییوها فوتوفن دیگری هم برای بهبود عملکرد خود دارند، پیش دریافت یا پیش واکنش (prefetching) است. در حقیقت CPU با بهرهمندی از این تکنیک میتواند سریعتر به دستورالعملهای ذخیرهشده در حافظه دسترسی پیدا کند تا به دادههای موردنیاز خود قبل از اینکه به آنها نیاز پیدا کند، دسترسی پیدا کند. به بیان سادهتر بخش پیش واکنش در حقیقت واحدی است که CPU تلاش میکند در آن دستورالعملهای بعدی را که باید اجرا کند و همچنین دادههای موردنیاز آنها را زودتر از زمانی باید به آنها دسترسی پیدا کند، پیدا کند.
درصورتیکه CPU تشخیص دهند دستورالعمل بعدی نیازمند دادهای است که در کش وجود ندارد، به حافظه رم مراجعه میکند و پس از دریافت داده موردنظرش، آن داده را در کش خود ذخیره میکند. دلیل نامگذاری فرایند پیش دریافت هم همین موضوع است.
یکی دیگر از ویژگیهای خاص سیپییوها که حتماً باید به آن اشاره کنیم، وجود مدارهای شتابدهنده وظایف خاص در سیپییو است که شتابدهندهها (Accelerators) نام دارند. شتابدهندهها در حقیقت مدارهایی هستند که تنها وظیفه آنها، انجام یک وظیفه جزئی و کوچک در سریعترین زمان ممکن است. ممکن است این مدارها برای انجام این وظیفه به بهترین شکل ممکن، از روشهایی مثل رمزگذاری، رمزگشایی فایلهای چندرسانهای و یادگیری ماشینی استفاده کند.
اگرچه CPU میتواند تمام این کارها را خود بهتنهایی انجام دهد، اما مسلماً چنانچه یک واحد اختصاصی برای انجام این کار در اختیار داشته باشد، عملکرد بسیار بهتری خواهد داشت. اجازه دهید برای فهم بهتر این موضوع مثالی را بیان کنیم که هر فردی تقریباً میتواند بهراحتی آن را بفهمد.
همان طور که میدانید برخی از کامپیوترها و لپتاپهای ارزانقیمت فاقد کارت گرافیک مجزا هستند و فعالیتهای پردازشی را با استفاده از پردازنده گرافیکی ادغامشده در CPU انجام میدهد؛ مطمئناً پردازندههای گرافیکی ادغامشده درCPU میتوانند بسیاری از فعالیتهای پردازشی را بهراحتی و بدون هیچگونه مشکلی انجام دهند؛ اما واضح و مشخص است سیستم در صورت برخورداری از کارت گرافیک مجزا، قدرت پردازشی بسیار بالاتری خواهد داشت. با پیدایش شتابدهندهها و استفاده از آنها در CPU، یک هسته CPU فضای بسیار کمی از کل تراشه را اشغال میکند.
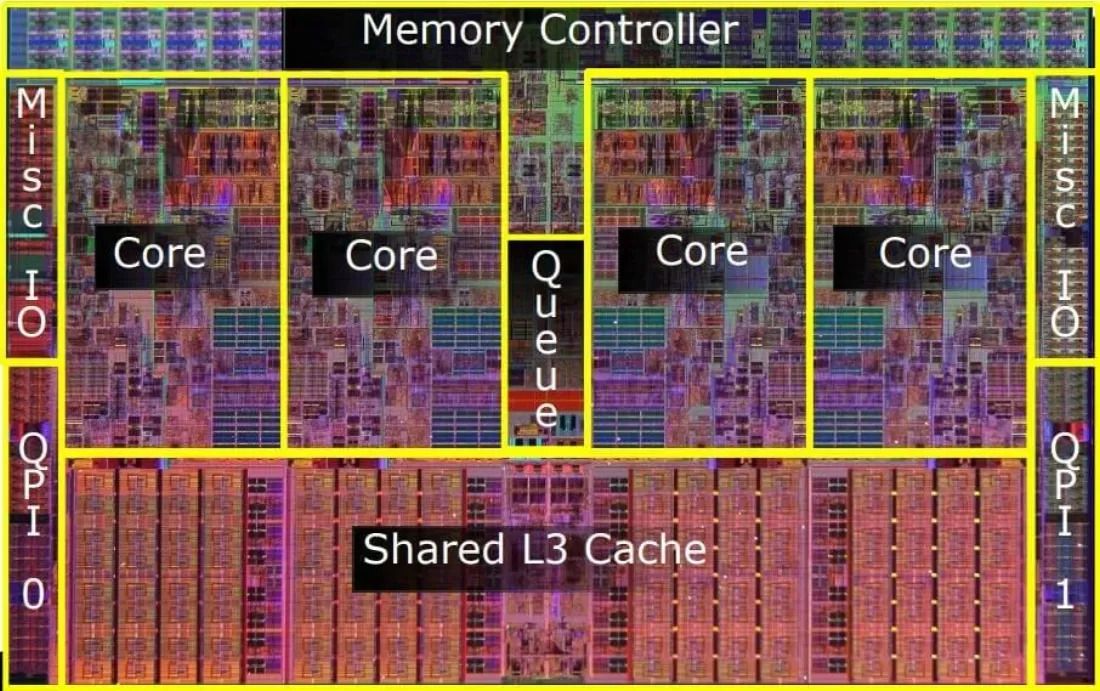
تصویر زیر تصویر یک سیپییوی اینتل متعلق به چند سال پیش است همانطور که میبینید بخش عمدهای از فضای تراشه سیپییو توسط هستهها و حافظههای کش آن اشغال شده است؛ اما در تصویر زیر این تصویر که ساختار یک سیپییوی بسیار جدیدتر AMD در آن به تصویر کشیده شده است، به وضوح میبینید که فضای اشغالشده توسط سایر قطعات CPU در مقایسه با فضای اشغالشده توسط هستههای آن، بسیار بیشتر است.
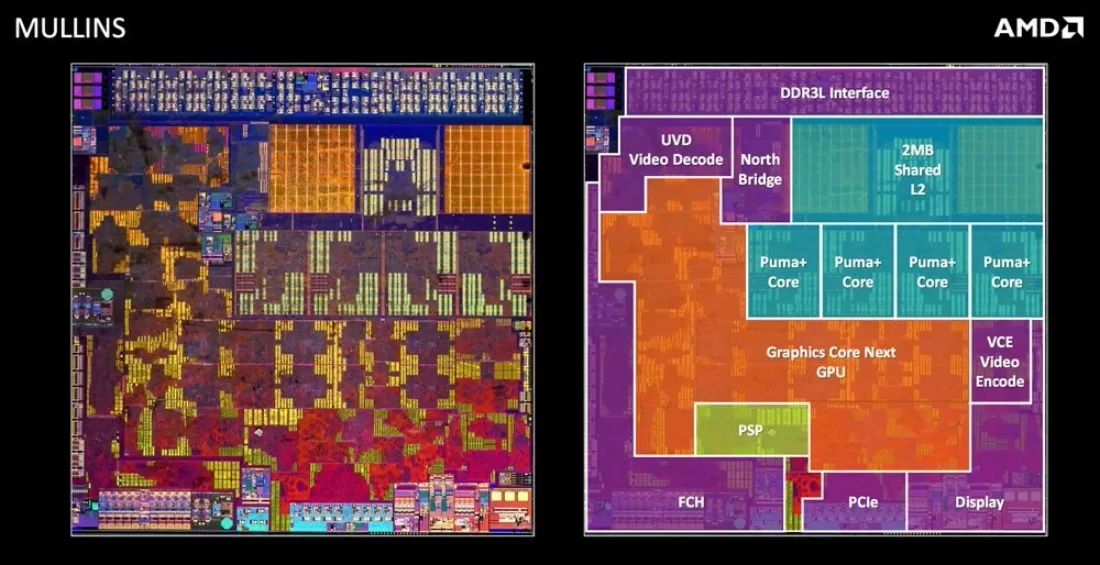
بررسی ساختار سیپییوهای چندهستهای
آخرین مبحثی که قصد داریم در این مقاله به آن بپردازیم، سیپییوهای چندهستهای است تا ببینیم یک سیپییوی چندهستهای چگونه از به هم پیوستن چند سیپییو مجزا تشکیل میشود. قطعاً طراحی و ایجاد سیپییوی چندهستهای ساده نیست و نمیتوان تنها با قرار دادن چند هسته یکسان در کنار یکدیگر، یک سیپییوی چندهستهای ایجاد کرد. در ضمن همانطور که تبدیل یک برنامه تکرشتهای به برنامه چندرشتهای امکانپذیر نیست، متصل کردن چند سختافزار به یکدیگر نیز آسان نیست.
دلیل آسان نبودن اتصال چند هسته CPU به یکدیگر، مستقل بودن آنها از یکدیگر است. در ادامه این موضوع را بیشتر برای شما باز میکنیم.
اجازه دهید ساختار یک سیپییوی چهارهستهای را بررسی کنیم. یک سیپییوی چهارهستهای باید بتواند دستورالعملها را چهار برابر سریعتر از سیپییوهای تکهستهای اجرا کند. درضمن به چهار رابط اتصال مجزا به حافظه سیستم نیز نیاز دارد. همچنین باید این توانایی را نیز داشته باشد که بخشهای مختلف دادههای یکسان را بهصورت مجزا پردازش کند.
طبیعتاً برای طراحی چنین پردازندههایی، مسائلی مثل انسجام و پایداری باید از ابعاد مختلف بررسی شوند و چالشها و مشکلات مرتبط با آنها بررسی شود. همچنین برای طراحی آنها به دو سوال مهم پاسخ داده شود که به شرح زیر هستند:
- چنانچه دو هسته درحال پردازش دستورالعملی باشند که هر دو در حال استفاده از دادههای یکسانی باشند، هستهها باید چگونه تشخیص دهند که کدام یک از دستورالعمل دارای مقدار صحیح است؟
- درصورتیکه یک هسته دادهای را تغییر دهد اما آن داده در زمانی که دستورالعمل باید توسط هسته دیگر اجرا شود، به آن هسته نرسد، چه اتفاقی رخ میدهد؟
به دلیل اینکه هستهها دارای کشهای مجزایی هستند که ممکن است مقداری از دادههای ذخیرهشده در آنها با یکدیگر همپوشانی داشته باشند (یکسان باشند)، برای برطرف کردن تداخلات بین آنها باید از الگوریتمها و کنترلرهای پیچیدهای استفاده شود.
در ضمن زمانی که تعداد هستههای یک CPU افزایش مییابد، پیشبینی صحیح دستورالعملهای انشعاب نیز اهمیت بسیار زیادی پیدا میکند؛ زیرا هرچقدر تعداد هستههای پردازش کننده دستورالعملهای مختلف بهصورت همزمان بیشتر شود، احتمال اینکه یکی از آنها درحال پردازش دستورالعمل انشعاب باشد، نیز بیشتر میشود؛ بنابراین ممکن است جریان دستورالعمل هر لحظه تغییر کند.
معمولاً هستههای مجزا دستورالعملها را از رشتههای مجزایی دریافت و پردازش میکنند. چنین کاری باعث کاهش وابستگی بین آنها میشود. به همین دلیل ممکن است در برخی از مواقع برخی از هستهها بهشدت کار کنند و در مقابل سایر هستهها تقریباً هیچ فعالیتی نداشته باشند. با مراجعه به تسک منیجر ویندوز و بررسی عملکرد سیپییوی سیستم خود و هستههای آن میتوانید چنین اتفاقی را بهوضوح مشاهده کنید.
لازم به ذکر است که اگرچه تقسیم وظایف سیپییو بین هستههای آن در حالت کلی باعث بهبود قابلتوجه عملکرد آن میشود؛ اما همبشه هم نتیجه مثبتی ندارد؛ زیرا بسیاری از برنامهها برای فعالیت CPU با استفاده از چند رشته طراحی نشدهاند. همچنین ممکن است در برخی از مواقع خاص عملکرد کلی CPU در زمانی که تنها یک هسته کار میکند در مقایسه با زمانیکه کار بین هستههای مختلف تقسیم میشود، بهتر باشد!
طراحی فیزیکی
تاکنون تنها در مورد طراحی معماری CPU توضیح دادهایم؛ زیرا بخش عمدهای از پیچیدگی CPU مربوط به همین قسمت از طراحی آن است. اگرچه طراحی فیزیکی CPU بهاندازه طراحی معماری آن پیچیده نیست؛ اما این بخش هم پیچیدگیهای خاص خود را دارد.
CPU بهمنظور هماهنگسازی و همگامسازی (سینک) تمام قطعات موجود در پردازنده، از سیگنال کلاک استفاده میشود. پردازندههای مدرن معمولاً دارای فرکانس ۳ و ۵ گیگاهرتز هستند و چنین ساختاری در دهه اخیر تغییری نکرده است. در هر یک از این سیکلها میلیاردها ترانزیستور داخل تراشه خاموش و روشن میشوند.
بهرهمندی از کلاکها برای کسب اطمینان از اینکه هر یک از مراحل لولهکشی پیشرفت لازم را داشتهاند و اینکه تمام مقادیر در زمان درست نمایش داده میشوند، ضروری است. کلاک مشخص میکند یک CPU در هر ثانیه قابلیت پردازش چه تعداد دستورالعمل را دارد. درضمن افزایش فرکانس CPU در هنگام اورکلاک شدن آن هم باعث افزایش سرعت آن میشود و هم باعث کاهش مصرف و دمای آن در حین فعالیت میشود.

حرارت بزرگترین دشمن CPU است. با افزایش دمای قطعات دیجیتالی الکترونیکی ریز ترانزیستورهای مورداستفاده در آنها بهتدریج از بین میروند و در صورت که دمای سیپییو در حین فعالیت آن کاهش داده نشود، ممکن است این قطعه آسیب جدی ببیند. به همین دلیل تمام سیپییوها به سیستم خنککننده و از بینبرنده دما مجهز میشوند. پایه سیلیکونی CPU تنها ۲۰ درصد از فضای سطح فیزیکی آن را اشغال میکند. وجود فضای کافی روی سطح پردازنده از یک سو باعث میشود دمای تمام سطح کاملاً به هیت سینک منتقل شود و از سوی دیگر فضای لازم برای نصب پینهای بیشتر بهمنظور برقراری ارتباط CPU با سایر قطعات را نیز فراهم میکند.
سیپییوهای مدرن دارای هزاران پین ورودی و خروجی در پشت خود هستند؛ در حالی که یک تراشه موبایل تنها چند صد پین دارد؛ زیرا اکثر قطعات محاسبهکننده این تراشهها در داخل آنها قرار دارند. در حدود نیمی از پینهای CPU برای انتقال جریان برق موردنیاز قطعات و سایر پینها برای برقراری ارتباط CPU با سایر قطعات ازجمله رم، چیپست، هارد سیستم، دستگاههای متصل شده به مادربرد از طریق رابط اتصال PCI Express و سایر دستگاهها استفاده میشود. لازم به ذکر است ممکن است پینها طراحی متفاوتی داشته باشند.
سیپییوهای ردهبالا و قدرتمند در هنگامیکه با تمام توان خود کار میکند، جریان زیادی بهاندازه ۱۰۰ آمپر یا حتی بیشتر مصرف میکنند. برای تأمین چنین نیرویی باید صدها پین در تمام قسمتهای پشت CPU نصب شود. این پینها معمولاً روی صفحات طلایی نصب میشود تا قدرت رسانایی الکتریکی آنها افزایش یابد. سازندگان مختلف سیپییو برای چیدمان پینها روی محصولات متنوع خود از طراحیهای مختلفی استفاده میکنند.
برای اینکه بهتر متوجه توضیحات بیانشده بشوید، اجازه دهید ساختار سیپییوی اینتل Core 2 متعلق به سال ۲۰۰۶ را بهصورت ساده و مختصر بررسی کنیم؛ البته برخی از قطعات مورداستفاده در این CPU منسوخ و از رده خارج شدهاند؛ اما جزئیات طراحیهای جدیدتر در دست نیست.
بررسی را با قسمت بالای CPU شروع میکنیم. در این قسمت کش دستورالعمل و TBL (Translation lookaside buffer) دیده میشود. TBL یا بافر پهلو - نگر ترجمه، به CPU کمک میکند مکانی از حافظه را که میتواند دستورالعمل موردنیاز خود را در آنجا پیدا کند، بهدرستی تشخیص دهد. چنین دستورالعملهایی در کلش L1 دستورالعمل ذخیره میشوند و سپس به پیش رمزگشا (Predecoder) ارسال میشوند. معماری ۳۲ بیتی بهشدت پیچیده و متراکم است؛ بنابراین برای رمزگشایی آن باید مراحل زیادی طی شود. در ضمن پیشبینیکننده انشعاب و پیشدریافت هر دو تلاش میکنند مشکلاتی را که ممکن است در هنگام اجرای دستورالعملهای بعدی ایجاد شوند، در زمان مناسب تشخیص دهند.
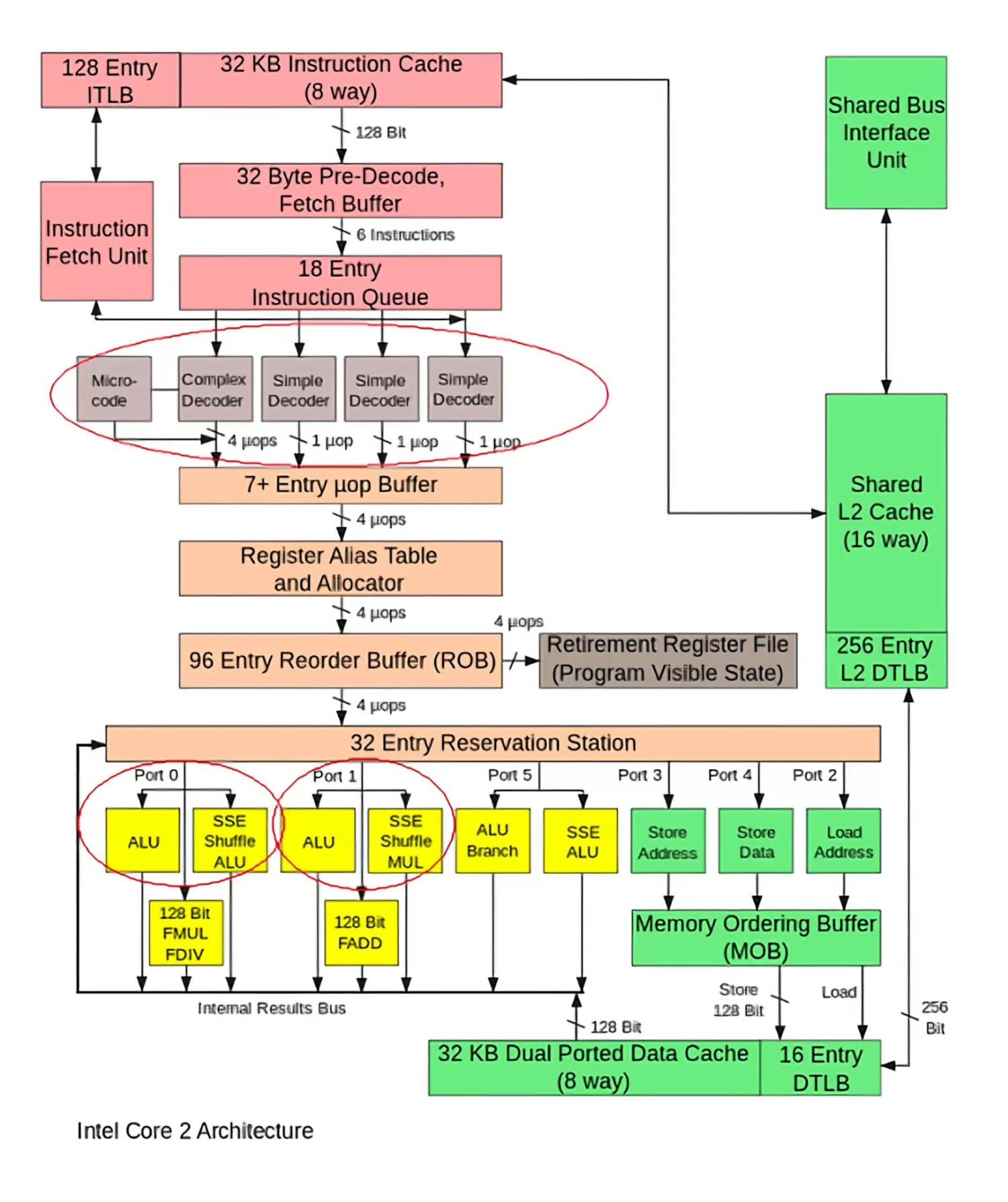
پس از ارسال دستورالعملهای موردنیاز سیپییو به پیش رمرگشا، آنها به یک صف دستورالعمل منتقل میشوند و خارج از ترتیب توسط CPU اجرا میشوند (یعنی همان فرایند اجرا شدن دستورالعملها توسط سیپییو خارج از ترتیب قرارگیری آنها در صف که قبلاً در مورد آن توضیح دادیم).
صف دستورالعملها دربردارنده دستورالعملهایی است که CPU به آنها نیاز دارد. زمانی که CPU تشخیص دهد بهترین دستورالعمل ممکن برای اجرا شدن در آن لحظه چه دستورالعملی است، دستورالعمل موردنظر به شکل یک عملیات کوچک یا بهاصطلاح ریز عمل (micro-ops) رمزگشایی میشود. با وجود اینکه ممکن است دستورالعمل رمزگشاییشده دربردارنده وظیفه پیچیدهای برای CPU باشد، اما وظیفهای جزئی و ساده محسوب میشود و CPU میتواند آن را بهراحتی تفسیر کند
این دستورالعملها در مرحله بعدی به جدول نام مستعار رجیستر (Register Alias Table) و ROB و ایستگاه رزرو (Reservation Station) منتقل میشود. وظیفه این سه بخش کمی پیچیده است و توضیح در مورد این موضوع فراتر از سطح این مقاله است؛ اما به بیان ساده این سه قسمت در فرایند پردازش دستورالعملها خارج از ترتیب آنها، برای کمک به مدیریت وابستگیهای بین دستورالعملها استفاده می شوند.
یک هسته CPU دارای تعداد زیادی واحد محاسبه و منطق و همچنین تعداد زیادی پورت حافظه است. عملیات ورودی تا زمانی که یک واحد محاسبه و منطق یا پورت حافظه برای استفاده در دسترس قرار گیرد، در واحد رزرو نگهداری میشوند. زمانی که این دو قطعه سختافزاری در دسترس قرار گرفتند دستورالعمل با کمک داده ذخیرهشده در حافظه کش L1 پردازش میشود. در مرحله بعدی نتایج خروجی ذخیره میشوند و CPU در آن زمان آماده است دستورالعمل بعدی را شروع کند.
اگرچه این مقاله با هدف توضیح در مورد نحوه کار هر یک از انواع CPU تهیه و تدوین نشده است؛ اما سعی کردیم با ارائه آن فهم ساختار پیچیده این قطعه پیچیده را تا حدودی برای شما ساده کنیم. متأسفانه همانطور که گفتیم AMD و اینتل اطلاعات دقیقی در مورد نحوه کار سیپییوهای خود منتشر نمیکنند و اطلاعات ارائهشده در این مقاله تنها بخش بسیار کوچکی از اطلاعات بسیار گسترده در مورد سیپییوها است.












